Introduction
News sources today are diverse: newspapers, radio stations, websites and more. They are also widely accessible. The internet has allowed us to collect news from all around the world, covering practically any topic. From anywhere, we can read Russian sports news and hear about the latest celebrity gossip from Argentina.
The goal of this project is to organize these news outlets into communities. We want to answer the following questions:
- Can we find a meaningful way to group news outlets?
- Once found, is there a way to find which attributes characterize these groups?
- Do some attributes strongly predict how groups are formed?
- Can we visually convey the identity of such groups?
The main idea
What do newspapers that cover the same topics share ? It seems reasonable that similar newspapers would cite the same people. For example, two science magazines will likely cite authors of the latest research. US political news will cite politicians.
Our hypothesis is that two journals that cite the same people are very likely to be similar. For example, they might discuss the same topic or be located in the same geographical area. This will form the basis of our analysis.
How did we do it?
We used the 2020 Quotebank dataset, which contains a list of quotes. Each quote is associated with its likely speaker and the news outlet in which the quote appeared. Additional data about the speakers and the news outlets was extracted from the Wikidata platform.
As a first step, we used Quotebank to link news outlets to the people they cite. Using the data it provided, we were able to create news communities. With our method, news outlets are grouped by the authors of quotes. If two news outlets cite the same person many times, they are more likely to end up in the same group.
A technical parenthesis
A good starting point is to look at the distribution of the data we are going to use. In our case, the distribution of the number quotes per journal and of the number of different people cited per journal.
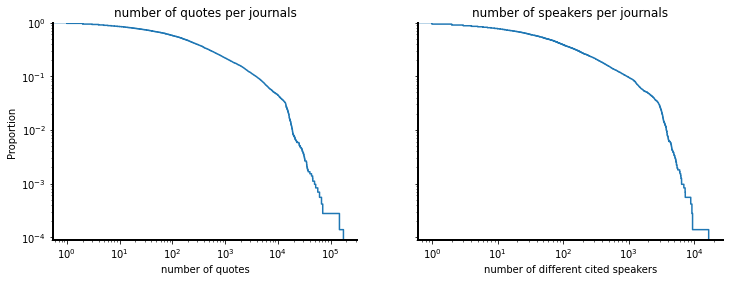
The figure shows that the distributions are heavy tailed. We find heavy tailed distributions in many real world phenomenons, for examples the distribution of city sizes, of people friends in a network or the distribution of word counts in a text. As our data share a similar distribution with these phenomenons, it is also likely to share other properties with them. For instance, we know that the way we mesure similarity works especially well with text and that real networks have tendency to form local clusters. It is a hint we are in the good direction.
Let’s explore the results!
Our clustering method yields 15 clusters, let’s explore them! The labels for clusters in the following visualizations were picked by hand, based on the results of our semantic analysis.
We first inspect the distribution of news outlets per cluster:
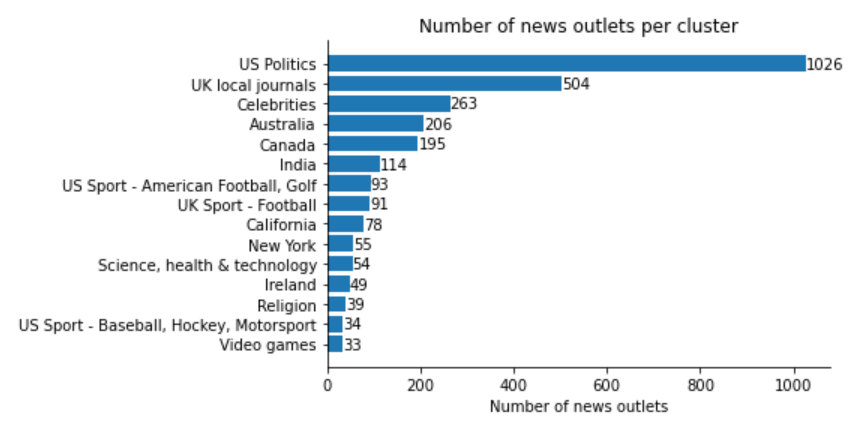
Quotebank contains mostly english-speaking media, which is reflected. Now we inspect the distribution of quotes per cluster:
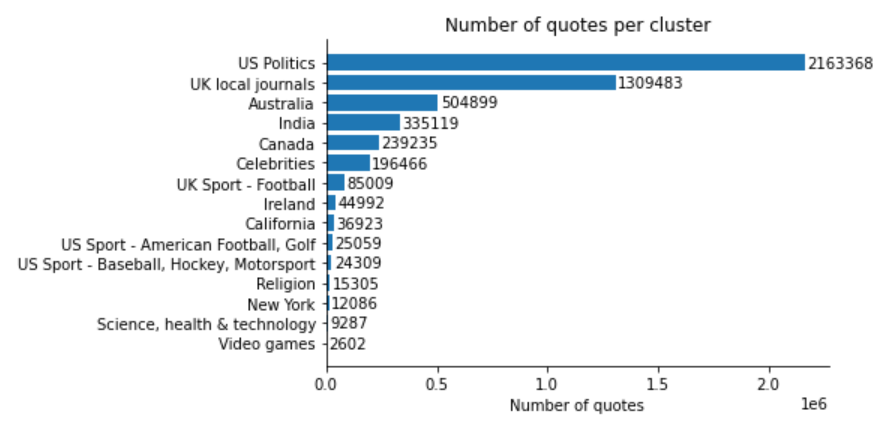
An first important observation is that the number of quotes is not entirely correlated with the number of news outlets. For example, although the “Celebrities” cluster has the third most news outlets, it is only 6th for the number of quotes. Let’s inspect the average number of quotes per outlet for each cluster instead:
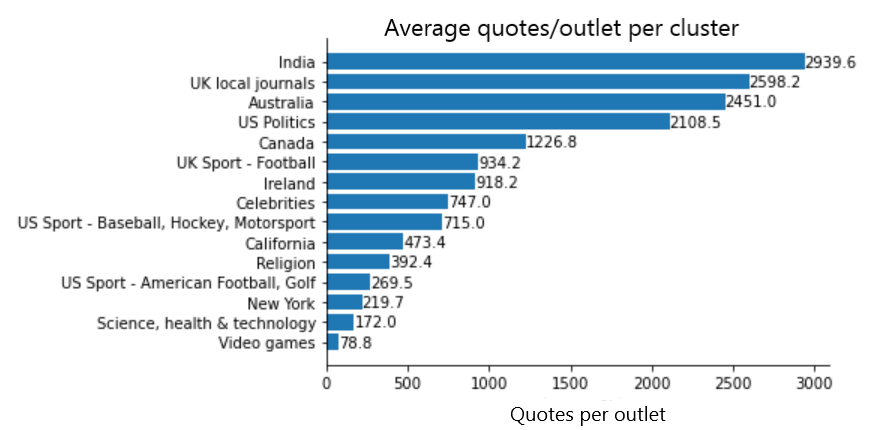
Interestingly, the different communities do not cite people at the same rate. Gaming news outlet cite the least amount of people. This could be explained by the fact that the gaming scene is not personality based. In contrast, more traditional outlets like those in the Indian, Australian, US and UK are comparatively more likely to cite. Let’s have a look at our clusters!
Click on the cluster names to show information panel. Drag to rotate the graph.
Analysis
Before diving into individual clusters, here are some interesting observations to be made:
Cluster separation
Quotebank contains mostly english quotes. One could expect english-speaking countries to be heavily represented and discussed. Indeed, we observe a nice geographic separation between our groupings. The biggest english-speaking countries (India, Canada, Australia, Ireland, UK) each have their own cluster. Regarding the United States, we even have a semblance of West/East coast separation as California and New York media have been grouped separately.
But clusters are not only separated geographically. We also notice cultural and sports groupings. This suggests that politics and news media have low overlap with news outlets discussing “leisure” topics. For example, we find clusters for video games, religion, celebrities, sports, etc…
Insight into the United States
As a majority of journals included in Quotebank are related to the United States, the groupings related to the country give insight into American culture. If we make the assumption that media covers the main areas of interest of the local population, we can deduce popular aspects of US life. Aside from politics, we observe that religion and celebrities are big interests of the US population. Furthermore, there is a large interest in sports; notably, American football, Basketball, Hockey, Golf, Baseball, and motorsports.
We can also infer some of the nation’s most famous individuals or best athletes by looking at the top speakers. For example, Tiger Woods is the most quoted speaker in the “Golf” group, with 2.11% of all quotes. This might indicate his strong reputation in the sport.
Our clusters indicate that New York and California are important geographic locations of the country. Each have their dedicated cluster. This can be seen by looking at the top journals for the New York cluster (gothamist.com, newyorkupstate.com, brooklyneagle.com) and the top speakers for the California cluster (Gavin Newsom, Eric Garcetti, Alex Villanueva).
We see that Quotebank has given us a vast array of information about the life and politics in the United states.
Donald Trump
Amazingly, Donald Trump is a top quoted speaker in 10 of our 15 clusters. In the “religion” cluster, he is even the second most quoted individual, after Pope Francis himself! He has dominated political discussion in the United States for 2020 with around 7% of quotes attributed to him in our “US politics” grouping, with his presidential opponent Joe Biden trailing in second with less than 2% of quotes in comparison.
In our local clusters, New York and California, he remains in the top 3 cited individuals with around 3% of quotes. Trump is also popular in the international media. He once again appears in the 10 most cited individuals in our journal groupings for Ireland (4th with ~2%), Australia (10th with ~1%), UK (3rd with ~1.5%), India (2nd with ~3%), and Canada (2nd with ~2.5%).
This shows the wide influence of the former US president. His prevalence in clusters not even directly related to US Politics highlights the profound impact the figure had on the worldwide media landscape.
Health
For a number of groupings, health seems to be a recurring topic. Given the ongoing coronavirus pandemic, a large media interest on sanitary measures and health discussion can be observed.
Many government health officials appear in the top speakers of their respective clusters. Some notable individuals include Tedros Adhanom Ghebreyesus (WHO Director-General), and Anthony Fauci (US Medical Advisor). Both are repeatedly cited in several groups.
One can also notice that both are highly cited in the “US Politics” cluster. This is linked to health being a major political subject in 2020, in the United States at least.
Geography
As we have seen above, location is the most prevalent defining attribute of our communities. Indeed, even though news has largely moved online today, it is natural that the stories outlets cover remained local.
We found it interesting to plot the locations of our journals on a world map. The visualization below lets you explore how communities are distributed around the globe. For news outlets without a precise location, we use the center of its country of origin.
Using this interactive map, we notice that naming the clusters according to location was indeed a good choice. Clusters named after a location have most of their news outlets in the given location.
What about clusters not named after a location? Video Games and Celebrities are still mainly located in the US and the UK. This is probably because most english-speaking news outlets come from these countries.
Conclusion
In this data story, we managed to find meaningful groupings of news outlets. We did so by linking news outlets together by the individuals they cite. These groups were represented visually in interesting and meaningful ways.
We were able to identify what defines each group based on closer inspection of the most quoted speakers, the top journals, quote semantics and keyword analysis.
This gave useful insights into the relationships between news outlets. We saw how news outlets are strongly geographically linked, how the US and its major politicians influence news worldwide, and how the current Coronavirus pandemic predominates news topics.
As further work, we could use the methods developed for this project to automatically classify news outlets based only on their citations. Additonally, by looking at which groups mention a given topic or individual, we could provide a more granular insight into it is treated in the news.